Main content
Top content
Rekonfigurierbarer Superskalarer RISC-V-Prozessor
Im Rahmen dieses Projektes entwickeln wir ein neuer RISC-V-Kern mit superskalarer Out-of-Order-Architektur. Der Prozessorkern wird in VHDL entworfen, der wichtigsten Hardwarebeschreibungssprache vieler europäischer Mikroelektronik-Projekte und zentraler Bestandteil der Mikroelektronik-Ausbildung an Universitäten. Zu den wichtigen Merkmalen der Architektur gehört neben vielfältigen Konfigurationsmöglichkeiten zur Entwurfszeit die Unterstützung von Hardware-Rekonfiguration zur Laufzeit, um die Ressourceneffizienz des Kerns weiter zu verbessern. Darüber hinaus unterstützt der Prozessor benutzerdefinierte Befehle, wobei der Schwerpunkt hier aktuell auf der Beschleunigung von Algorithmen des maschinellen Lernens liegt.
Architektur des Prozessorkerns
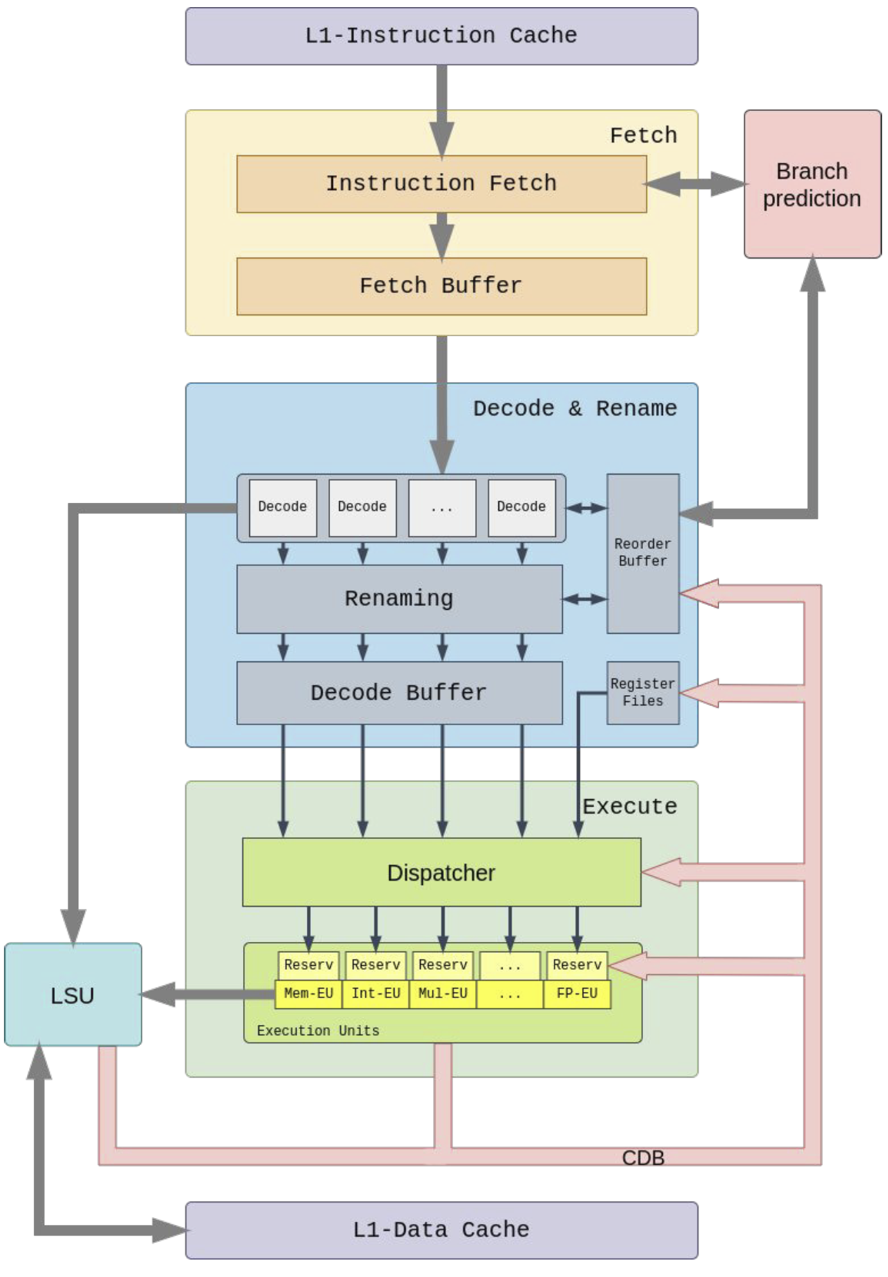
Die grundsätzliche Struktur des Kerns folgt den üblichen Architekturansätzen für superskalare Prozessoren. Die interne Befehlsverarbeitung beginnt mit einer Fetch-Stufe, die eine bestimmte Anzahl von Befehlen pro Taktzyklus aus dem Befehls-Cache abrufen kann. Die Adresse des nächsten Instruktionspakets, das geholt werden soll, wird von der Sprungvorhersageeinheit ermittelt, die eine spekulative Ausführung ermöglicht. Die Instruktionen werden anschließend dekodiert, und für jede Anweisung wird ein Eintrag im Reorder-Buffer reserviert. Die nachfolgenden Registerumbenennung löst die Abhängigkeiten zwischen den Anweisungen auf und ermöglicht die Verarbeitung der Befehle außerhalb der Programmreihenfolge. Anschließend werden die Befehle an die Reservierungsstationen der Ausführungseinheiten weitergeleitet; dort warten die Befehle auf die für die Ausführung erforderlichen Daten, die über den Common Data Bus bereitgestellt werden. Die Adressen für Lade- und Speicheroperationen werden in der Memory-Execution-Einheit berechnet und dann an die Load-Store-Einheit als Schnittstelle zum Daten-Cache übergeben.
Konfiguration zur Entwurfszeit
Viele Aspekte des Prozessorkerns sind zur Entwurfszeit konfigurierbar. Dazu gehören die Bitbreite der Architektur, d. h. 32 oder 64 Bit, und die Anzahl der parallel verarbeiteten Instruktionen. Dies wirkt sich direkt auf die Anzahl pro Takt geholter Befehle (Issue Width) am Anfang des Datenpfads aus und setzt sich bei der Dekodierung und Umbenennung fort. Die Größe von Puffern, wie dem Reorder-Buffer und den Register-Files, kann entsprechend der Anforderungen konfiguriert werden, die sich z. B. aus der gewählten Issue-Width des Kerns ergeben, während die Anzahl der Schnittstellen des Reorder-Buffers und der Registerdateien automatisch an die gewählte Ausgabebreite angepasst wird. Ein weiterer Parameter, der zur Entwurfszeit konfiguriert werden kann, ist die maximale Anzahl der beim Einschalten verfügbaren Ausführungseinheiten (diese können zur Laufzeit neu konfiguriert werden).
Rekonfiguration zur Laufzeit
Zur Laufzeit kann die Hardwarearchitektur des Prozessorkerns partiell verändert werden, um die Ressourceneffizienz einer FPGA-basierten Implementierung weiter zu steigern. Dabei konzentriert sich die dynamische Rekonfiguration des Kerns primär auf die Ausführungseinheiten, da die superskalare Architektur deren Austausch mit begrenzten Architekturänderungen ermöglicht. So kann sich der Kern an die Anforderungen der aktuell ausgeführten Anwendungen anpassen. Beispielsweise würden Programme mit vielen Gleitkommaoperationen von zusätzlichen Gleitkommaeinheiten profitieren, während andere Programme eher Vorteile aus einer erhöhten Anzahl von Multiplikations- oder Divisionseinheiten ziehen. Mit Hilfe der dynamischen Rekonfiguration ist es möglich, Hardware-Ressourcen von Ausführungseinheiten freizugeben, die derzeit nicht genutzt werden. Diese Ressourcen können dann für wichtigere Ausführungseinheiten oder für anwendungsspezifische Beschleuniger genutzt werden.
System-on-Chip-Integration
Für die Systemintegration verwenden wir den LiteX System-on-Chip-(SoC-)-Generator, der den Entwurf kompletter Soft-SoCs ermöglicht. LiteX bietet eine große Anzahl von IP-Cores für die Peripheriekomponenten des Prozessorsystems, wie z. B. DDR-Speicher-Controller und Ein-Ausgabe- und Netzwerk-Schnittstellen. Die Nutzung von LiteX erleichtert die flexible Integration des Prozessorkerns und seiner Peripherie in verschiedene FPGA-Plattformen und Anwendungsszenarien. Darüber hinaus können unsere auf STANN basierenden Deep-Learning-Beschleuniger auf diese Weise in das Soft-SoC integriert werden.
